超线程
当英特尔® 超线程技术处于激活状态时,CPU 会在每个物理内核上公开两个执行上下文。这意味着,一个物理内核现在就像两个“逻辑内核”一样。超线程技术就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了 CPU 的闲置时间,提高的 CPU 的运行效率。
虽然采用超线程技术能同时执行两个线程,但它并不象两个真正的 CPU 那样,每个 CPU 都具有独立的资源。当两个线程都同时需要某一个资源时,其中一个要暂时停止,并让出资源,直到这些资源闲置后才能继续。因此超线程的性能并不等于两颗 CPU 的性能。根据 Intel 官方文档反馈,理论情况下在服务器应用程序中可提升 30% 的性能。
怎么确认机器是否开启超线程
通常情况下,我们只需要通过 /proc/cpuinfo 即可确认机器是否开启超线程。当相同的 physical id 和 core id 出现两次时,即表示机器开启了超线程。
以图 1 为例,在 /proc/cpuinfo 中共可以找到 48 个 CPU,根据 physical id 和 core id 的组合,我们可以画出 CPU 架构图如下图 2。其中如 0-24/2-26/../23-47 表示相同 core id,启用了超线程后操作系统看到的逻辑 CPU 对。
CGROUPS
cgroups 是 Linux 内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对 cpu,内存等资源实现精细化的控制,目前市面上相当流行的轻量级容器 Docker 就使用了 cgroups 提供的资源限制能力来完成 cpu,内存等部分的资源控制。
笔者目前主要的工作内容是为公司提供数据库私有云服务,为了有效充分的利用服务器资源,我们会利用 cgroups 对资源进行隔离,根据业务需求提供不等规模的机器资源。其中对 cpu 的隔离是通过 cpuset.cpus 来进行的,通常情况下,我们会保留头部数个 cpu,如 CPU 0-CPU 5 做为系统保留 CPU。其它 CPU 则按顺序,如将 6,7,8、9,10,11,12,13,14 分配给两个不同的实例。
为了业务的可用性考虑,我们的 CPU 分配还是比较充份的,通常 50% 是我们的一个相对安全水位。所以大多数情况下,上面的按序分配并不会带来什么问题。本文主要是探讨极端情况下上述 cpu 分配方式可能造成的问题。
问题
-
由于共用了物理 CPU,容器之间可能存在 CPU 争抢:
以数据库为例,明明 A 实例的负载并不高,但有时候会忽然「卡」那么一下或者刷个慢查询,但业务并没有发生变化,DBA 也无法追踪到不合理的 SQL 或索引缺失等情况

图 3. 逻辑 CPU 分配案例一 以上图 3 为例,假设我们给 Container A 绑定了 2, 3, 4 共 3 个 CPU,给 Container B 绑定了 26, 27, 28 共三个 CPU,可以看到 2-26, 4-28, 3-27 分别共享了一个物理核心(core id 相同)。根据对超线程的理解:
当两个线程都同时需要某一个资源时,其中一个要暂时停止,并让出资源,直到这些资源闲置后才能继续,假设 Container A 的负载较高,则 Container B 是有可能受到影响并导致出现 cpu 等待的情况的,反映到业务,则是:不知道为什么抽风了。 -
高负载情况下,隔离资源的实际性能表示与标称值不符:

图 4. 逻辑 CPU 分配案例二 以上图 4 为例,假设 0, 1, 2, 45, 46, 47 为保留 CPU(不明确分配实际业务),其它 CPU 按顺序每 6 个一组分配至不同的业务容器,我们可以猜测分配到 21, 22, 23, 24, 25, 26 这 6 个 CPU 的容器会有较少的超线程资源争抢,预计会有更好的性能表现。
下图为某业务的实际测试图,在施加具备让容器满载压力情况下,具备较少超线程争抢的容器拥有较好的性能。这在大多数情况下可能并不是好事:
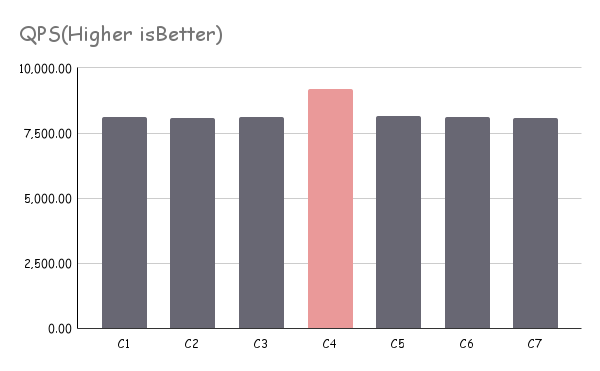
图5. 某业务使用“图 4. 逻辑 CPU 分配案例二”压力测试情况 - 个别节点拥有较高性能可能造成业务上线压力评估的数据失真;
- 对于分布式场景,各节点的能力承载存在明显不一致可能造成分布式系统的降级甚至雪崩;
上述两个问题本质是一样的,都是因为超线程的争取造成的压力不一致、资源抢占。虽然大多数情况下通过资源的预留减少了上述问题发生的概率,但当问题发生时,一线技术人员极难排查,只能以疑难问题或偶尔抽风等玄学又无奈的口径进行解释。对技术人员的业务技能储备有非常高的要求,需要对硬件架构、操作系统、业务架构等多方面都有较清晰的了解。
推荐分配方案
-
大多数情况下,如果可以预见系统不会出现满载(如达到 70% 或以上),或只有个别实例会出现满载的情况按系统内 CPU 顺序直接分配绑定并不会带来明显问题。这种方式不管是理解还是运维实现,都是最直接和可快速落地的。
相关技术人员需了解此知识点,当出现资源抢占问题时可以有效进行分析排查。
-
如果对于资源隔离、容器间相互影响有较高质量要求的情况下,建议 CPU 以偶数倍进行绑定,并确保同一个 core id 下的两个逻辑 CPU(超线程 HT)被分配绑定至同一个容器/实例。这种方案下,需要对 CPU 的分配进行合理编排调度。(下图以 4 个 CPU 为一组,确保每一个物理核心超线程后的两个逻辑 CPU 被分配至同一组)

图 6. 逻辑 CPU 分配案例三 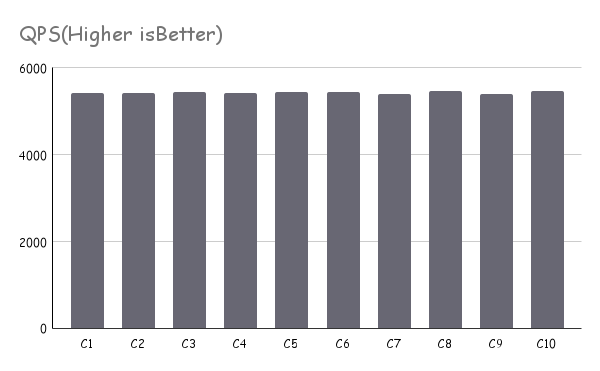
图7. 某业务使用“图 6. 逻辑 CPU 分配案例三”压例测试情况 -
对于 CPU 时间有更细粒度或更精准控制的场景可以考虑通过 CPU 时间分片进行限制,可参考 CFS Bandwidth Control,这里不展开讨论。
评论
评论使用 GitHub Discussions 承载;留言需要 GitHub 账号。